이전 시간에는 크롤링 대상 사이트를 탐색했었는데요(다른 사이트도 선택해 비슷하게 진행가능).
저는 신한투자증권 장내 채권 사이트를 선정했었습니다.
https://www.shinhansec.com/siw/wealth-management/bond-rp/590401/view.do
이번 시간에는 선정한 사이트 채권 정보를 가져오는 내용을 리뷰해볼게요.

위에 보이는 테이블은 스크롤을 내리면 자동으로 채권들이 리젠되는 구조로 되어있습니다.
테이블에 존재하는 모든 채권을 가져오려면, 맨 아래에 있는 채권까지 다 리젠이 되어야 되기 때문에, 테이블 스크롤을 가장 아래로 내리는 작업이 필요합니다. 이 과정에서 Selenium(셀레니움)을 사용해 자동으로 스크롤을 맨 아래로 내리고, 모든 요소를 긁어오겠습니다.

div 태그에 tableScroll 클래스로 달려있습니다. 이걸보고 div.tableScroll하여 테이블에 접근할 수 있겠다는 것을 알 수 있는데요,
우리는 테이블 스크롤을 맨 밑까지 내리기 위해, div.tableScroll을 활용할 겁니다.
맨 밑까지 내린 후, 각 채권명, 현재가, 거래량, 수익률을 가져오겠습니다.
1) 채권명
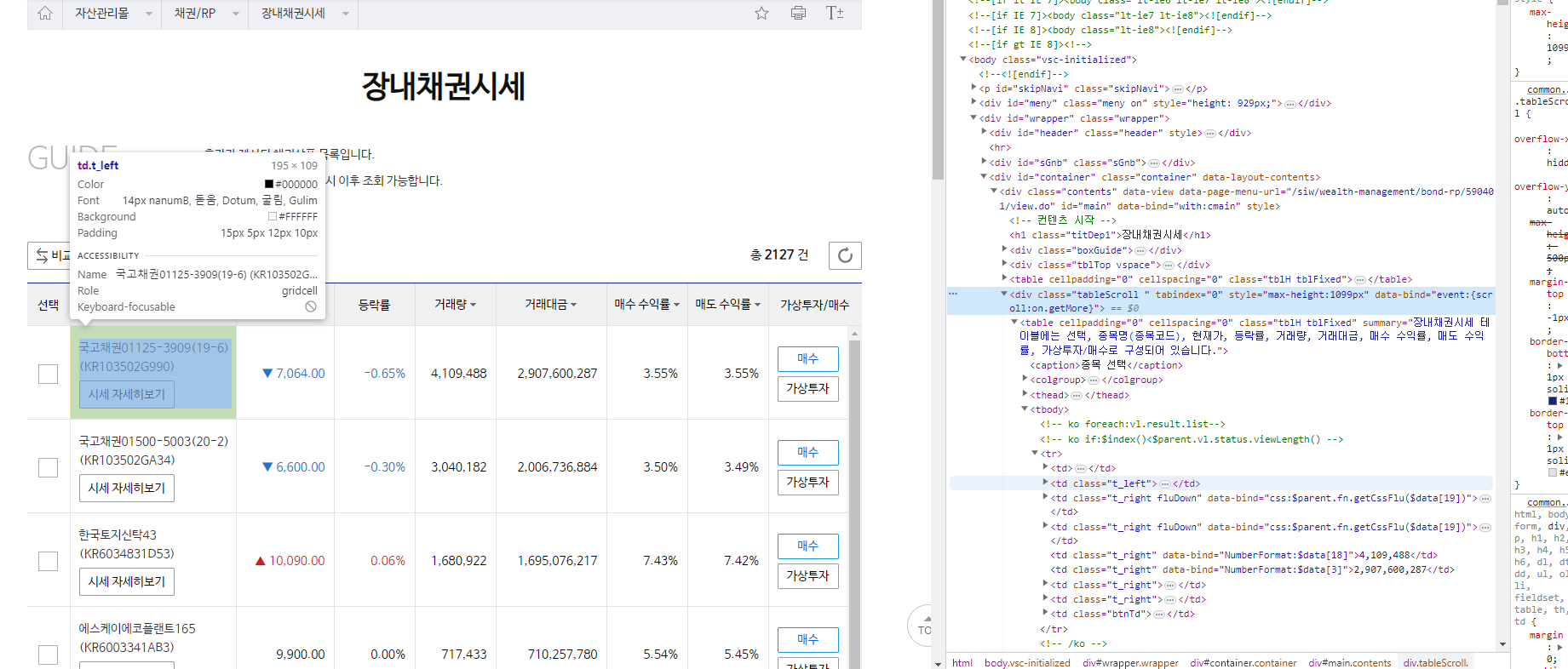
td 태그의 t_left 클래스라는 것을 알 수 있습니다. 우리는 td.t_left로 해당 채권명 전체 리스트를 가져올 수 있음을 알 수 있고, 이 중에서 채권 이름만 가져오기 위해 안 쪽으로 더 진입해야 합니다.

td 태그의 t_left 클래스 내에는 2개의 a 태그가 더 존재함을 알 수 있는데, 이 중 첫번째 a 태그를 펼처보면 아래와 같습니다.

td 태그의 t_left 클래스 밑에 span을 가져오면 채권명을 가져올 수 있겠다는 생각이 듭니다.
2) 현재가

현재가도 비슷하게 구할 수 있습니다. 하지만 어떤 CSS를 통해 구해야될 지 잘 모르겠다면 마우스 오른쪽 클릭으로 Copy selector를 통해 CSS를 찾을 수 있습니다.
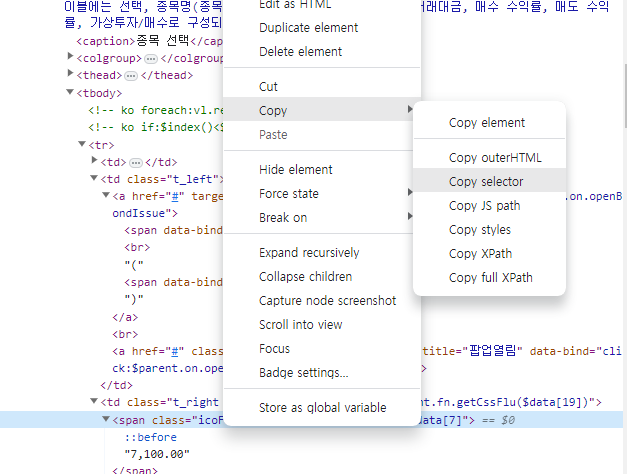
이 경우 아래처럼 나오게 됩니다.
#main > div.tableScroll > table > tbody > tr:nth-child(1) > td:nth-child(3) > span
우리는 td에서 세번째 위치에 있는 요소를 가져오는 td:nth-child(3)을 선택해 모든 현재가에 접근하겠습니다.
3) 거래량
같은 방식으로 td:nth-child(5)를 취하면 됩니다.
4) 수익률
같은 방식으로 td:nth-child(7)를 취하면 됩니다.
다음 시간에는 직접 구현해서 결과를 확인해보겠습니다.
'Python > Python 자동화' 카테고리의 다른 글
| pyqt selenium 채권 정보 크롤링 (3): python활용한 채권 데이터 크롤링 구현 (0) | 2023.07.03 |
|---|---|
| pyqt selenium 채권 정보 크롤링 (1): 데이터 수집 사이트 탐색 (0) | 2023.06.18 |
